
 Deutsch
Deutsch English
English Italiano
Italiano Español
EspañolPour faciliter le développement entre les projets, l’équipe qui développe le Webmail Infomaniak a regroupé le code des applications dans un dépôt unique (monorepo). Cette démarche vise à améliorer les processus de mise à jour, faciliter la collaboration et accélérer l’évolution de l’écosystème. Le Webmail est un projet pilote d’envergure avec plusieurs applications interconnectées (kDrive, Mail, Calendar, Contacts) et plus de 1 Million d’utilisateurs quotidiens. Nos développeurs racontent cette transition, ses bénéfices, ses challenges et aussi ses impacts négatifs.
La performance de nos solutions, nous allons aussi la chercher dans notre propre organisation et nos processus. Julien Arnoux, VP of Engineering chez Infomaniak
Pourquoi passer à une architecture monorepo ?
Le cycle de vie du Webmail nécessite d’adapter notre stratégie de référentiel de code. Jusqu’à maintenant, les différentes parties (projets, bibliothèques) du Webmail étaient développées dans des dépôts de code distincts. Une équipe faisait évoluer le code d’une bibliothèque pour son projet de façon autonome sans répercuter en temps réel les changements de versions sur les autres projets en cours. Ce suivi devenait complexe :
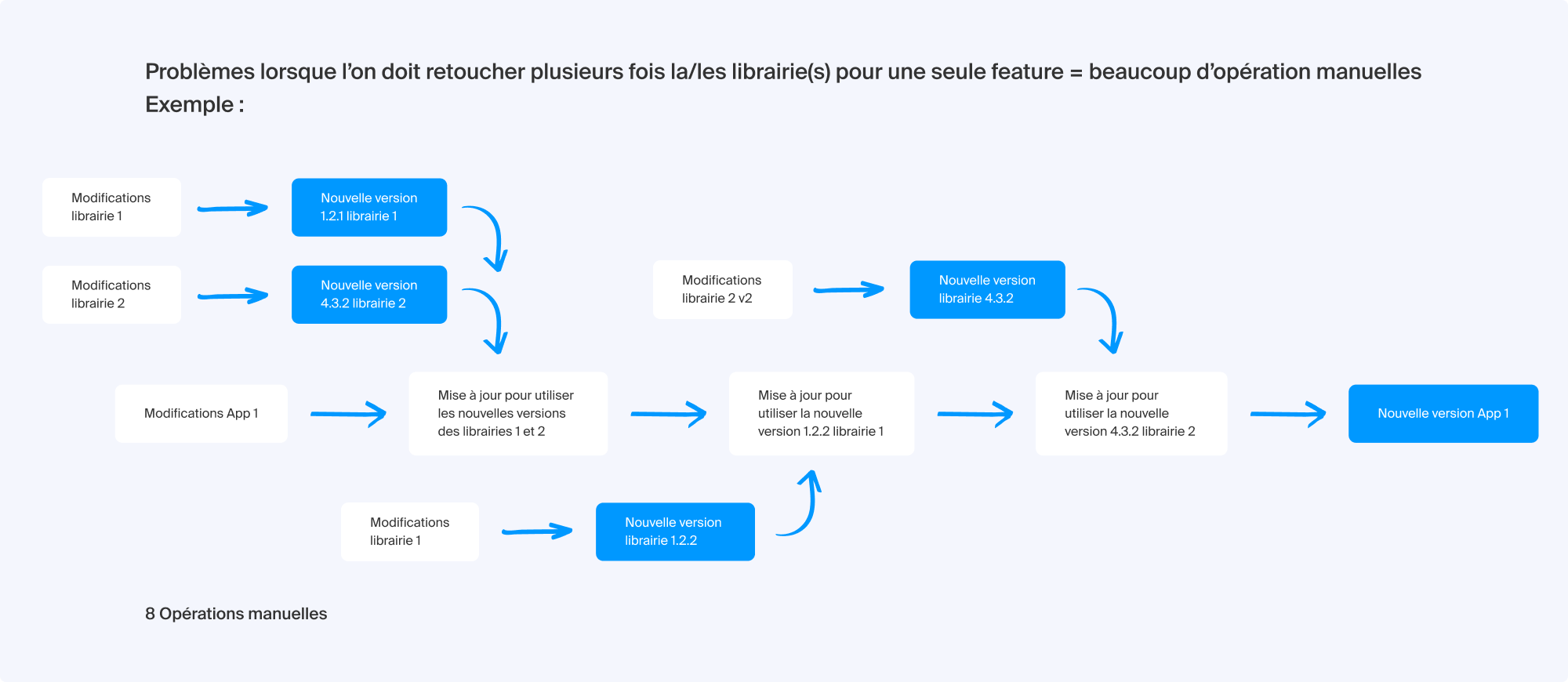
“Les développeurs qui travaillaient sur des modifications transverses devaient systématiquement repérer et aligner les versions de chaque librairie et projets modifiés manuellement. Cela pouvait engendrer beaucoup de manutention. L’idée était de s’affranchir de toutes ces étapes intermédiaires pour se concentrer sur le développement à proprement parler.” Zachary Volpi, Développeur Webmail chez Infomaniak
Les projets pouvaient aussi se désynchroniser si une équipe avait un cycle de publication plus rapide que celui des autres bibliothèques dépendantes. La lourdeur des opérations de publication et de mise à jour manuelles en multirepo augmentait aussi les manipulations fastidieuses et les risques d’erreurs au détriment de la création de valeur.
Les bénéfices de l’architecture monorepo
Avec ce nouveau socle, notre approche DevOps gagne en efficacité. Des cycles automatisés permettent de compiler, tester et déployer du code sans erreur (spectre des erreurs humaines notamment). Ces avancées permettent de fluidifier toutes les étapes de livraison des applications.
1. Mutualisation et validation du code simplifiées
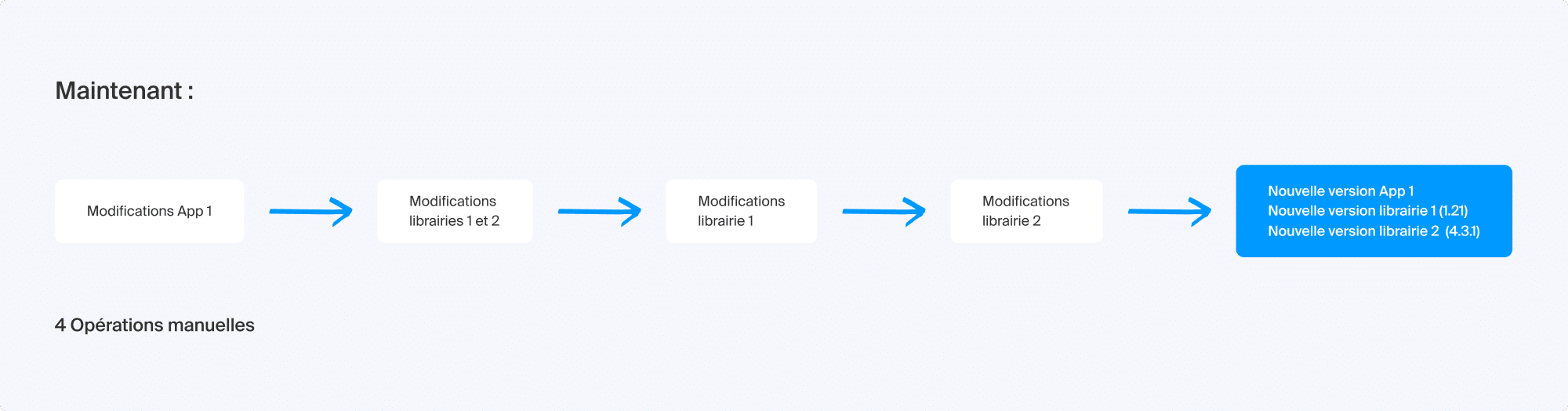
Avec une architecture monorepo, les versions du code source sont partagées entre toutes les parties du projet. Une seule modification prend effet partout sans risque de casser une fonctionnalité adjacente. Plus besoin de cibler la version appropriée pour chaque dépendance. Nos scripts détectent les projets liés par une mise à jour et lancent les processus de validation associés aux zones modifiées.
2. Gestion facilitée des processus DevOps
La centralisation du code permet la création de pipelines pour l’ensemble du projet avec un énorme gain de temps à la clé. Nos pipelines d’intégration continue (CI) et de livraison continue (CD) deviennent plus rigoureux avec des processus éprouvés, prédictifs et répétables. Ça facilite l’ajout de nouvelles portions de code.
Nous pouvons maintenant coupler des pipelines en fonction du stage (build, test, déploiement). Les jobs sont lancés en parallèle, ce qui était impossible ou fortement contraint en multirepo. Chaque jeu de test étant commun, le développement des fonctionnalités qui touchent plusieurs applications est beaucoup plus rapide.
3. Collaboration facilitée et meilleure vue d’ensemble
Les développeurs peuvent récupérer et intégrer l’ensemble d’une modification en cours, ce qui renforce la compréhension globale. Plus besoin de parcourir plusieurs projets pour détecter des problèmes cachés, tout est à portée de main. Nous modifions et testons dans la foulée, ce qui raccourcit la boucle de validation. Le changement de contexte est aussi plus aisé : un développeur travaillant sur plusieurs projets ou devant incorporer le travail d’un collègue peut comparer les différences beaucoup plus rapidement.
4. Amélioration de la qualité du code
Nous n’avons plus besoin de dupliquer, d’embarquer une bibliothèque dans un projet parent et de faire des allers-retours constamment. Avoir l’intégralité du code sous la main permet d’identifier plus rapidement les problèmes. Nous pouvons également alléger le poids des applications en supprimant le code mort sans craindre qu’il soit utilisé ailleurs. Le fait de partager un même environnement réduit les divergences entre les équipes.
Quand nous modifions une bibliothèque, ces vérifications sont d’abord effectuées : le code respecte-t-il les normes en vigueur ? Fonctionne-t-il comme prévu ? Ensuite, nous exécutons les tests des applications qui l’utilisent pour valider sa bonne intégration. C’est une approche en oignon (par couches), passant des tests les plus simples (unitaires) aux plus complexes (de bout en bout).
5. Accélération du développement
Le monorepo facilite la sortie régulière de nouvelles fonctionnalités. Nous récupérons les modifications des autres développeurs beaucoup plus vite. Avec l’automatisation des processus, cela rend les mises en production plus harmonieuses. La boucle de retour d’information étant accélérée, nous pouvons itérer plus rapidement.
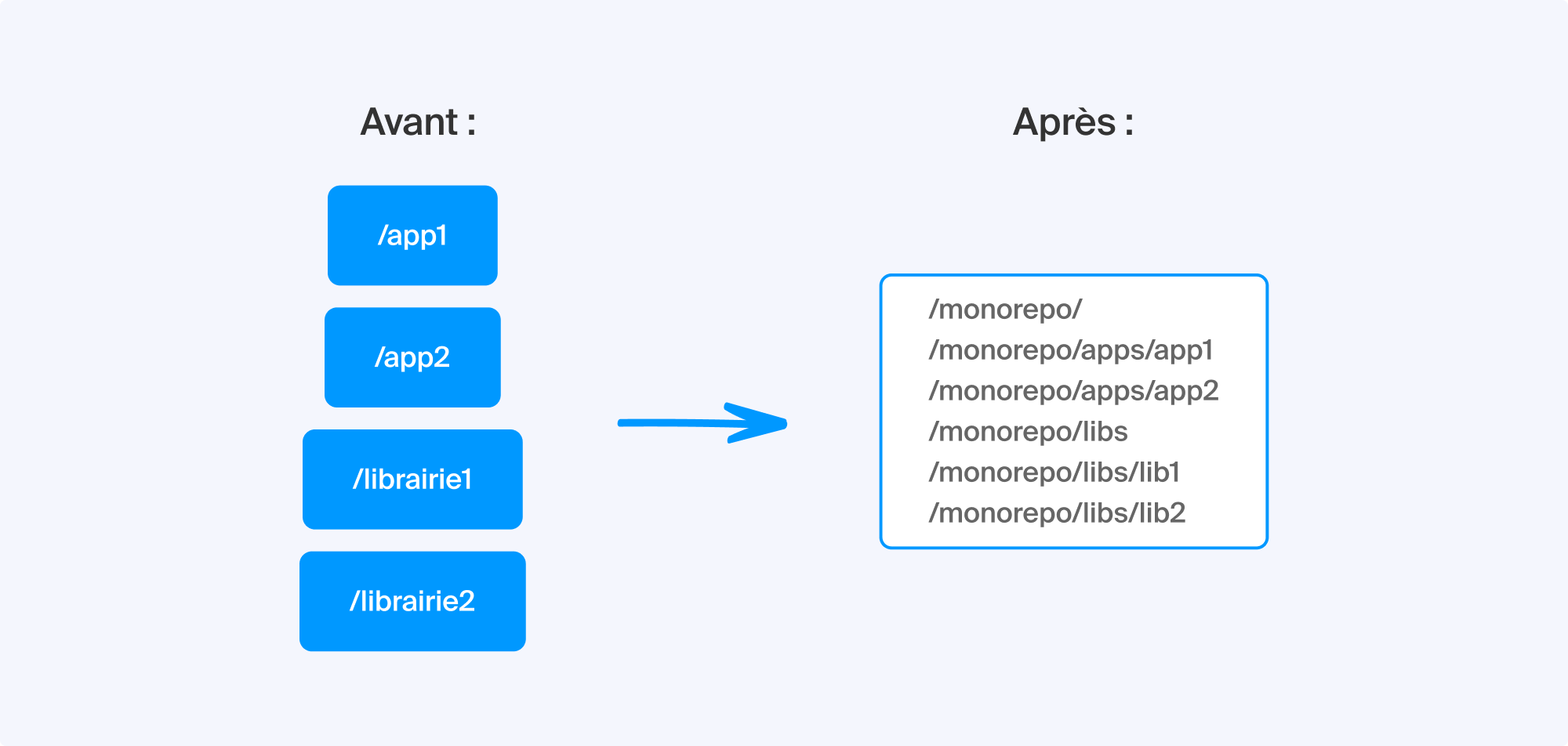
Passer au monorepo : qu’est-ce que cela change ?
Rien de mieux qu’un schéma pour illustrer l’impact du monorepo sur notre organisation :
Amélioration qui nécessite plusieurs modifications des différentes librairies utilisées dans le projet :
Avec le monorepo :
La mise en place du monorepo dans un environnement en production
Nous voulions rendre la transition totalement transparente pour nos clients et quasiment transparente pour les collaborateurs qui travaillaient sur le projet.
“Contrairement à un projet naissant, modifier l’organisation du code du Webmail impliquait d’énormes conséquences, car l’application est en production. C’est comme ouvrir un chantier sur une route principale.” Zachary Volpi, Développeur Webmail chez Infomaniak
Il a fallu découper la transition en plusieurs étapes pour éviter un trop gros changement qui aurait pu déclencher une indisponibilité de service, sans possibilité de revenir en arrière. Nous avons donc effectué un long travail de préparation et de validation :
- Découpage de la migration en plusieurs phases en intégrant l’impact potentiel pour les collègues.
- Test de chaque étape en amont lorsque cela était possible.
- Détail de chaque étape avec une liste de tâches “prête à l’emploi” pour le jour J.
- Planification des jalons de la migration lors de périodes de faible affluence.
- Simulation de scénarios de crise pour anticiper les problèmes et prévoir les actions à mettre en oeuvre.
Notre équipe a aussi élaboré des procédures de documentation des incidents pour permettre le rétropédalage dans une certaine mesure.
Le choix du PHP
Ce qui est DevOps est souvent plutôt écrit en bash ou en python, rarement en PHP. Les pipelines DevOps que nous allions mettre en place devaient être compréhensibles par tous nos autres collègues. Nos applications sont elles aussi écrites en PHP et il est tout à fait possible de l’utiliser pour du scripting. Nous avions aussi déjà des environnements d’exécution configurés et disponibles pour d’autres étapes. Il était donc plus simple de les réutiliser directement plutôt que de partir de feuilles blanches.
Trouver le bon rythme de basculement
Il ne fallait pas rester dans des phases de transition prolongées. Chaque tâche devait par conséquent se dérouler à un intervalle suffisamment long pour assurer la sécurité et la stabilité, mais relativement court pour ne pas induire de la fragilité dans le système.
Les principaux défis posés par la migration
Une migration sans retour en arrière
Cette démarche a eu un impact sur tout le workflow (structuration des étapes, extraction des portions communes, emplacement des fichiers, historique des modifications) et tous les environnements de travail de l’équipe Webmail (environnement de production, de développement, de test, de release de package, de notifications, etc.). Il était donc important que la phase de transition ne dure pas trop longtemps.
En multirepo, chaque modification sur un composant nécessite d’adapter et de vérifier manuellement chacune de ses dépendances. En monorepo, presque tout est automatisé : dès qu’un composant est modifié, tout le système se met automatiquement à jour. C’est un peu comme si on passait d’une transmission manuelle à une boîte automatique sur une voiture. Tout est plus simple ! Julien Arnoux, VP of Engineering chez Infomaniak
Penser et anticiper tous les scénarios
C’est paradoxal, mais il a fallu passer par une grande complexité pour tout simplifier. Le fait de centraliser le code implique de tout repenser. Pour définir les logiques de déclenchement des pipelines, nous devions comprendre leur impact sur chaque projet et développer la détection du contexte qui va avec, pour :
- les stages (Continuous Integration + Continuous Development)
- les jobs communs aux apps et bibliothèques
- les différents stages de build
- L’exécution des tests et validations des parties concernées
La principale difficulté était que nous ne pouvions pas tester toutes les étapes en conditions réelles, notamment celles sur l’environnement de production. Grâce aux possibilités de concentration des définitions de gitlab-ci, nous avons pu séparer nos différents scripts par thème et zone d’impact. Cela a réduit drastiquement la duplication de fichier et autres problèmes de copier-coller.
Bilan : monorepo ou multirepo ?
Était-ce une bonne idée de passer en monorepo ? La réponse est oui.
Cette nouvelle organisation apporte de gros avantages :
- Récupération simplifiée des modifications.
- Mutualisation de la configuration de certains outils.
- Réduction de la manutention lors de modifications sur de multiples applications.
- Simplification du développement : tout est présent au même endroit et il est bien plus simple de naviguer entre les zones.
Cette évolution a aussi des impacts négatifs :
- Il est moins évident de se repérer que dans un dépôt classique. La courbe d’apprentissage d’un nouvel arrivant s’en retrouve un peu plus longue.
- Il faut une bonne connaissance des outils CI / CD, notamment gitlab-ci, pour faire des ajustements sur les pipelines.
Les développeurs qui ont géré le passage au monorepo
Julien Arnoux, VP of Engineering chez Infomaniak (mais toujours les mains dans le cambouis) :
Je développe depuis mes 15 ans et j’aime tout ce qui touche à l’automatisation de nos workflows. Lorsque je développe et suivant le mood, je peux aussi bien écouter du hard-rock/metal que de la drum’n’bass. En fait, j’écoute un peu de tout, mais ces deux styles me donnent de l’entrain 😅
Zachary Volpi, Développeur full stack au sein de l’équipe Webmail :
J’ai commencé le développement en août 2014. J’aime avoir la vue (et la compréhension) de tous les aspects du développement d’application. Je recherche toujours des solutions pour simplifier un processus ou obtenir plus de performance. Pour accompagner mes sessions, j’adapte les musiques en fonction de ce que je veux faire : ça va du chill à la dub ou du métal. Côté références, je trouve le blog de logrocket très pertinent. Ils ont des articles très bien conçus sur des sujets très larges comme pointus. Sinon, je suis directement les canaux des outils que j’emploie (sur X & LinkedIn principalement).






Vous devez être connecté pour poster un commentaire.